In a previous post I discussed the maximum gap of draws from . There is a clear application of this problem to load balancing across many nodes. Given a dataset () of keys randomly hashed to one of nodes, we can expect that no node is responsible for more than keys. However, requests are not distributed equally across keys. A node storing a few popular keys may have much higher load than a node storing hundreds of less frequently accessed keys. Today we’ll calculate a bound for max load () assuming keys an arbitrary distribution over and that keys are assigned to nodes at random with a hash function, .
Because the standard Pareto distribution doesn’t have an moment when we’ll prefer the more complicated-looking, but much friendlier alternative. The truncated Pareto also maps onto the concept of a dataset with known size (i.e. ) quite well.
I’ll use the truncated Pareto distribution as a concrete example, although the bounds given will apply for any distribution. The density of a truncated Pareto defined on is as follows.
We can find a loose upper bound on by assuming the most frequently accessed keys all hash to a single node. This event occurs with very low probability (i.e. ) and isn’t all that useful.
I was quite proud of myself for this idea! Too big for my britches again.
Alternatively, we can treat as a random variable and estimate the mean and variance of the over . From there we can bound by bounding the total load generated by some number of instances of a random variable with the following properties:
This approach might be viable given a distribution with faster decaying tails, but in this case it produced a variance too high to be of any use. In general, methods that try to find by bounding the load on a fixed number of keys also consider the event that other nodes with fewer keys exceed that bound as well. This gets dodgy very quickly, I want no parts of it.
The most successful approach I tried involved re-framing the problem to focus more on load attributable to each node rather than sums of keys’ request frequencies. Consider a collection of functions . Each function takes arguments corresponding to whether the key hashes to the node and returns the load on that node. For a discrete distribution over we’ll define as follows:
For continous distributions we can define in terms of the difference in the CDF. i.e. ;
The following two properties then make it possible to apply McDairmid’s inequality on a collection of nodes.
Our hash function, distributes keys onto nodes all are independent.
Changing whether or not a single key () hashes onto node changes the load on by exactly .
McDairmid’s inequality (below) allows us to bound each about it’s expectation with tunable certainty, thus we can find an sufficiently large that the bound holds with high probability.
In the diagrams at left I:
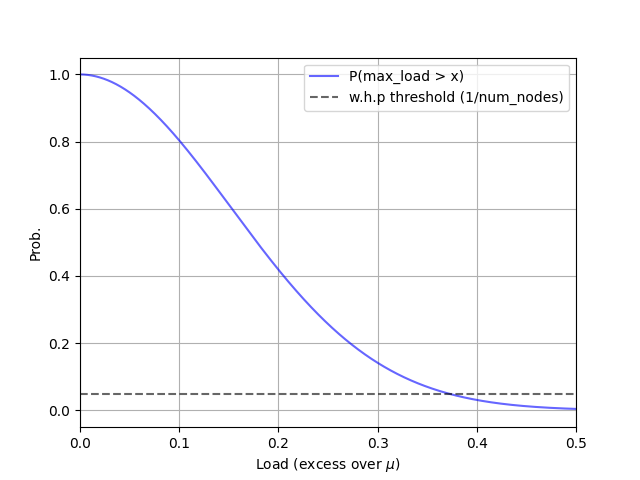
- Calculate an upper bound on that holds .
- Simulate under Pareto distributed load to verify these results…
# case #1: max. load d, n, a, mu, p = 2000, 20, 0.4, 1/20, [] t = ss.truncpareto(a, d) diffs = [ (t.cdf(x+1)-t.cdf(x))**2 for x in range(1,d+1) ] for i in range(1,d+1): p.append(np.exp(-(2*(i/d)**2)/sum(diffs)))# case #1 - simulation maxes = [] diffs = [ t.cdf(x+1)-t.cdf(x) for x in range(1,d+1) ] for j in range(20000): ns = collections.defaultdict(np.float64) for i, nid in enumerate( np.random.randint(0,n,d) ): ns[nid] += diffs[i] maxes.append(sorted(ns.values())[n-1])McDairmid’s inequality is closely related to Hoeffeding’s Lemma. While McDairmid’s only requires bounded differences, we have differences that are exclusively .
The remainder of this post works through an example using pareto distributed load and .
| : Upper Bound of With Pareto Request Patterns () |
|---|
|
| : Simulated With Pareto Request Patterns () |
|---|
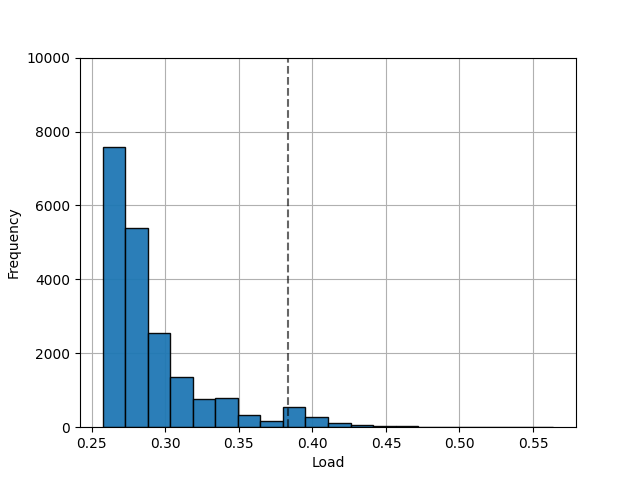 |
We can construct a tighter bound if we can assume the most requested keys all hash onto different nodes. Rearranging McDairmid’s inequality gives , a bound that’s conditioned on this event. To achieve the maximum load generated from keys must land on the same node as . This is quite unlikely.
# case #2: conditional max. load for i in range(0,n): cml = (0.5*np.log(n)*sum(diffs[i:]))**(1/2) cmls.append(cml)
| : Maximum Excess Load Given First Keys on Unique Nodes |
|---|
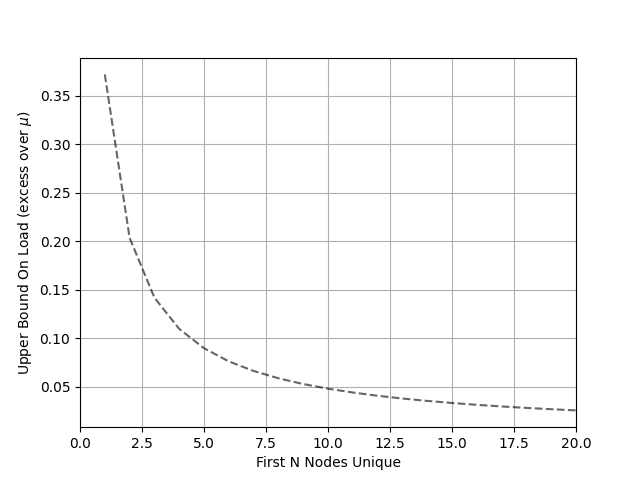 |