It’s been a productive last few days thinking about caches (theory, more theory). I haven’t written any code though, let’s change that. Today I’m going to make a change to that will allow me to benchmark with Pareto (or Zipf) distributed traffic. Because web traffic is far more likely to be Pareto (see: FIFO Queues Are All You Need, Table 1) than uniformly distributed, testing a cache under this alternative distribution more closely mimics real request patterns. This was a quick experiment and the change (in it’s entirety!) is below.
— The defaults (1) maximize entropy, (2) produce larger DBs faster and (3) maximize cache evictions. Recall that is the maximum entropy distribution with support on . Observations (2) and (3) follow from the fact that each key has of occurring in any interval of operations. If this was intentional, I can see why they’d do this. If not, path of least resistence, whatever…
— Multiple calls to are a performance hazard here. Anecdotally, on I was hitting 120,000 - 130,000 rps with either uniform or pareto distributed traffic. It does make a tiny difference, but it won’t overshadow the main point.
@@ -104,6 +104,7 @@ static struct config {
+ double zipf_shape;
} config;
@@ -378,11 +379,16 @@ static void randomizeClientKey(client c) {
for (i = 0; i < c->randlen; i++) {
char *p = c->randptr[i]+11;
+
size_t r = 0;
- if (config.randomkeys_keyspacelen != 0)
- r = random() % config.randomkeys_keyspacelen;
+ if (config.randomkeys_keyspacelen != 0) {
+ if (config.zipf_shape != 0) {
+ double z = config.zipf_shape;
+ r = (size_t)floor(
+ pow(1.0 - drand48() * (1 - 1.0 / pow(config.randomkeys_keyspacelen, z)), -1.0 / z)
+ );
+ } else {
+ r = random() % config.randomkeys_keyspacelen;
+ }
+ }
@@ -1442,6 +1448,8 @@ int parseOptions(int argc, char **argv) {
+ } else if (!strcmp(argv[i],"-z")) {
+ config.zipf_shape = strtod(argv[++i], NULL);— I refer to as and as in the text.
The only meaningful change is in , where I replace a random key distributed on with one distributed on . I apply the following transformation to to produce a Pareto variable with an upper bound at .
To test that my changes actually worked I ran a few small tests. Results presented below.
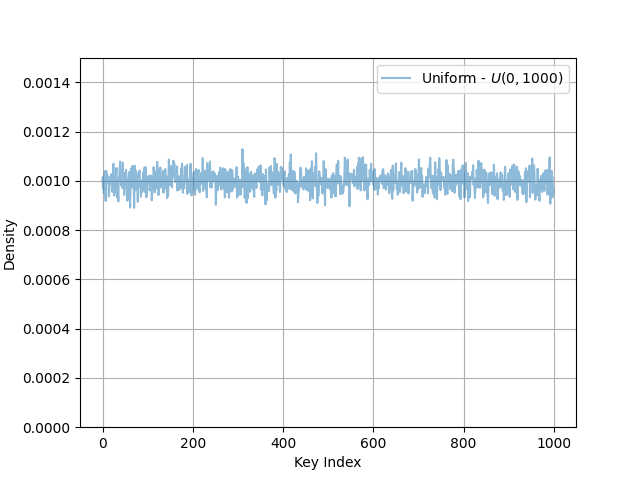
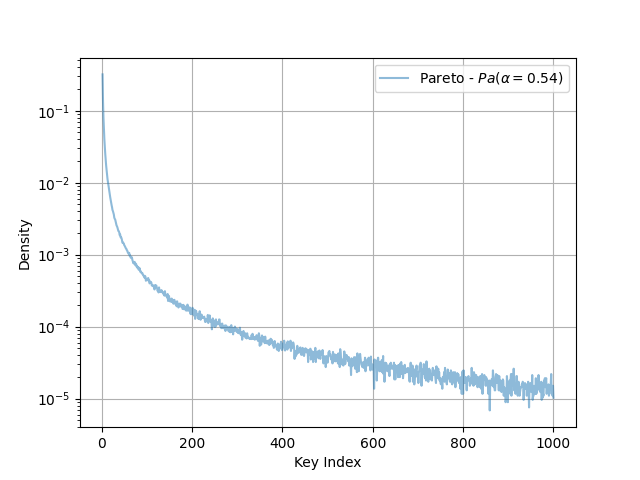
— I set Redis to AOF mode and fsync’d every 1s. I then wrote a small program to read the AOF and count the frequency of SET operations per key. The leftmost figure shows the results using the original benchmark methodology, the other figure shows the Pareto distributed results generated with the following command:
redis-benchmark -z 0.54 -r 1000 -n 500000 -t SET
Distributions Generated From Uniform & Pareto Benchmarking
|
|
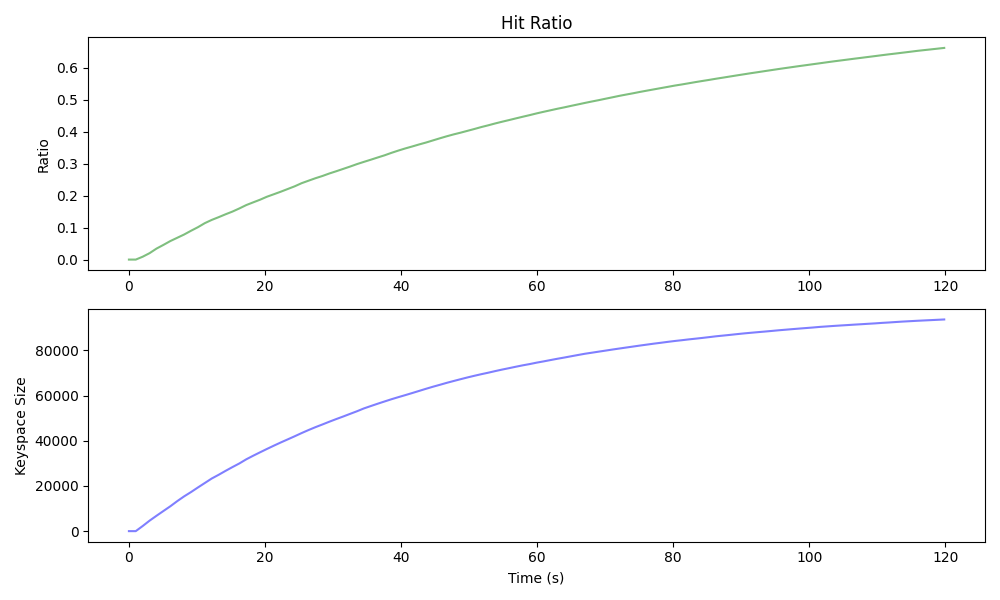
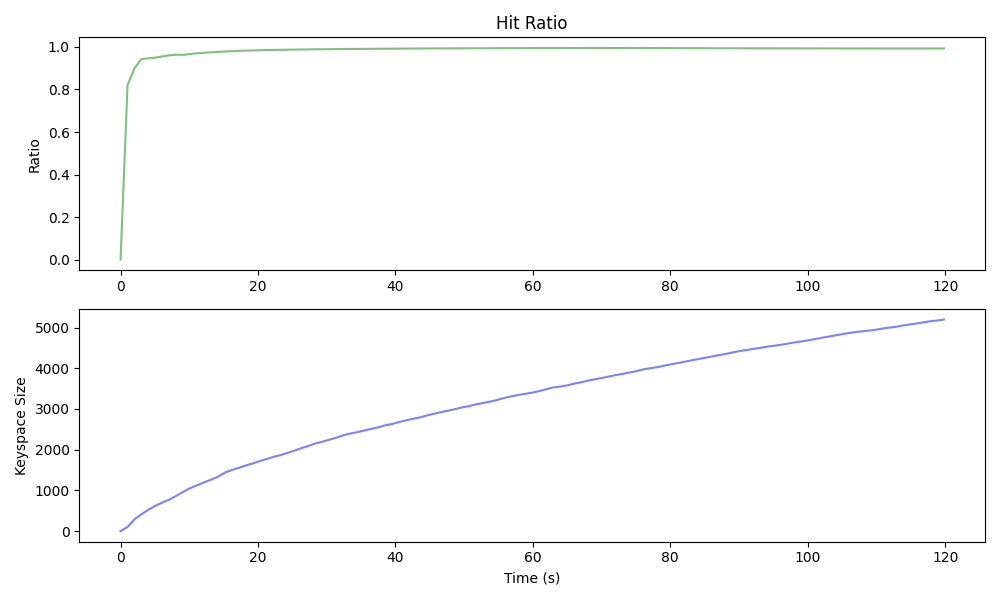
— I throttled the benchmarking script to of mixed and operations and then scraped , , and from the target DB. The uniform benchmark produced a DB that grew in size logarithmically and a hit-ratio that mirrored that growth 1:1. The Pareto distributed benchmark (below) produced a much smaller DB and achieved a higher hit-ratio much more quickly.
| Uniform Benchmarking |
 |
| Pareto Benchmarking |
 |
This addresses just the first of my two gripes with . My second gripe is that it doesn’t allow for correlated requests. In production, one can expect that operations on the same key closely follow one another. Given a stream of keys , we should expect .
This is a petty complaint and beefing up a client too much to do more stuff shouldn’t be a bottleneck that limits the efficacy your benchmarking tool. With that said, here’s how I might “fix” …
— The CDF of Truncated Pareto. Following my first change, we’d map a value from to using the inverse CDF. This figure shows the truncated Pareto with 16 keys and highlights the values of that correspond to the 3rd key.
| — Pareto Distributed Keys |
|---|
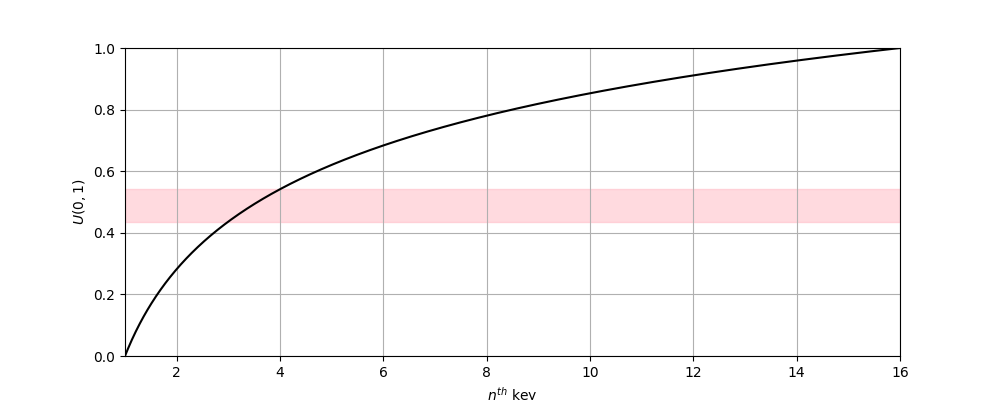 |
Rather than using , we’ll generate a random walk on . For any key, the probability of being chosen is no longer constant, it’s now a function of the position of the walk .
Where is the pdf of the Pareto, and is the distribution for the step on the walk. In practice, can be any easy-to-calculate random variable.
— A random walk on where each step is Laplace distributed w. . Any key is selected with approximately the same frequency as the original method, but selection probability for is maximized when the walk is near .
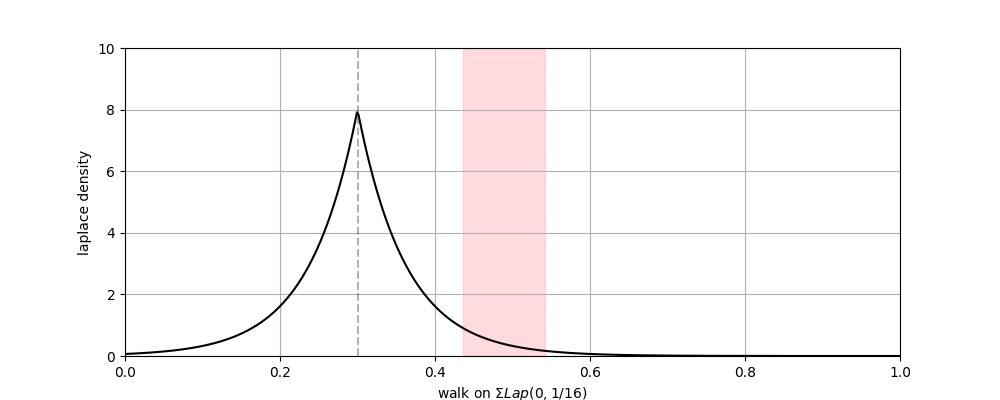
— The Laplace pdf. The probability the highlighted key is selected is the probability that the walk steps into the relevant range.
The Laplace is a convenient kernel choice because values are easily generated via. the inverse transform (either directly or difference of two exponential vars).
| — Laplace Random Walk over a Keyspace |
|---|
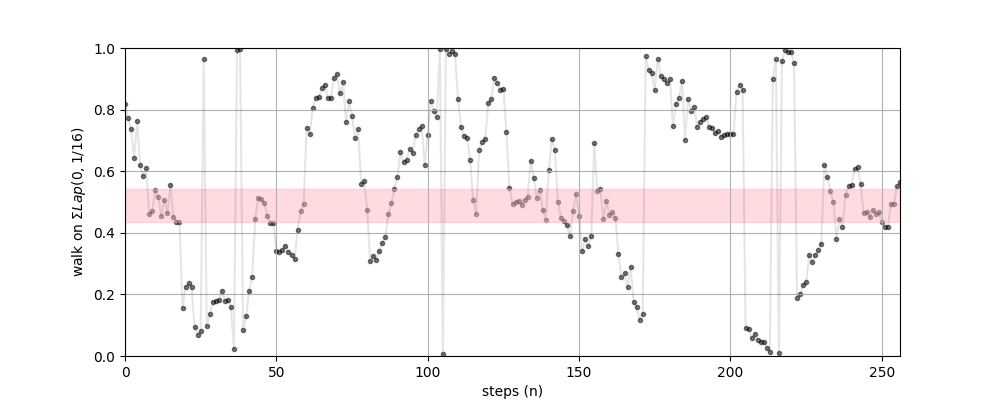 |
 |
This is an easy change that should just requires about 10 LOC added to . The next time I need it I’ll try to squeeze this in and see if it gives the desired results.