Although this post is about caching, I’ll ignore specific properties of the cache (e.g. size, eviction method) and focus on getting an upper bound on OHWs.
Today I’m going to find an upper bound on the number of “one-hit wonders” in a stream of requests. Given a set of keys, we’ll refer to keys that appear exactly once in requests as “one-hit wonders” (OHW). A high OHW count implies that a cache of these keys is likely filled with items that won’t be requested again. Being able to bound the OHW count is a good prerequisite step before designing a caching algorithm of our own.
We don’t need to limit ourselves to OHWs. A more general notion of efficiency may count the probability that a single key () appears at least once and no more than times. Assuming a key appears with a corresponding probability , the probability it appears more than once, but no more than times in a stream is as follows:
An even more useful cache efficiency metric could be calculated by estimating a distribution over the number of cache hits, misses or hit-ratio for each key.
When we restrict this to the OHW case () the expression becomes somewhat easier to work with.
Intuitively, a uniform distribution over all keys seems like a good first guess at maximizing . In the following section we’ll show that it’s a (near) optimal distribution.
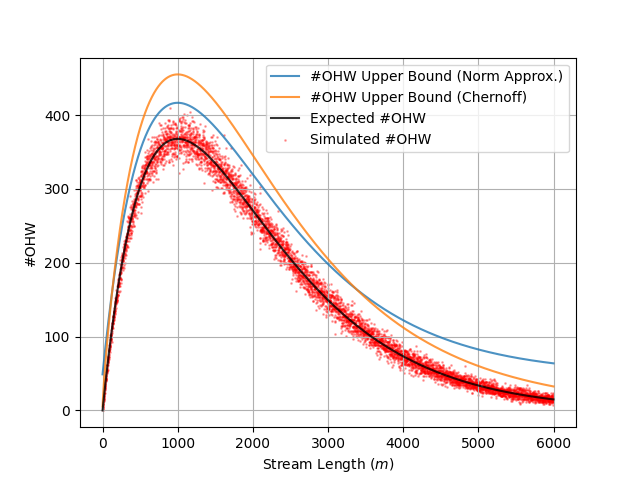
Because each key is equally likely to be an OHW, we can study the tails by approximating to the normal distribution.
Recall that the inverse CDF of is . We replace to get an upper bound.
Assuming an unbounded stream, we won’t know the value of or , but we can maximize the variance of the distribution by assuming . This implies and thus . We can then reference the inverse CDF of the normal distribution to find a bound that holds with high probability ().
This is a well-known bound for the sum of Bernoulli RVs. A good reference for this inequality is Mitzenmacher (Ch. 4.2). This proof shows this inequality for the more general case of Poisson trials.
Personally, I don’t want to mess around with . Let’s take a step back and derive a similar upper bound that only uses “nicer” functions. Rather than approximating the sum with the normal distribution, I’ll use a Chernoff Bound for the sum of Bernoulli variables.
To get an upper bound in terms of keys we solve for at some configurable level of certainty (e.g. ). This gives:
— Expected One-Hit Wonders and Bounds (1000 Unique Keys)
s, ohw = 10000, 0 for i in range(10**5): a = np.random.choice( [0, 1], s, True, [1-1/s, 1/s] ) ohw += (np.count_nonzero(a) == 1) ohw / int(10**5 * math.exp(-1)) # 0.99932
Consider a set of keys with and a stream of requests with . If we assign we’ll have . However, if we set we can achieve .
This suggests that on large streams () the maximum is achieved when . Intuitively, we can think of this as maximizing each of the first keys’ probability of one-hitting and then “sacrificing” the key.
I could show this more rigorously by setting up the full optimization problem with Lagrange multipliers, but the example at left makes the point clearly enough.
Over a set of keys this gives a maximum for . Slightly modifying our bound from the previous section gives us the following:
Although the key with probability is unlikely to be an OHW I include the to be safe. Regadless, now even if we don’t know we can bound over an arbitrarily long stream provided we know .
Related Reading:
In FIFO Queues are All You Need for Cache Eviction, the authors proposed a new class of caching algorithms based on data collected from the traces of several large caching systems.
From FIFO Queues:
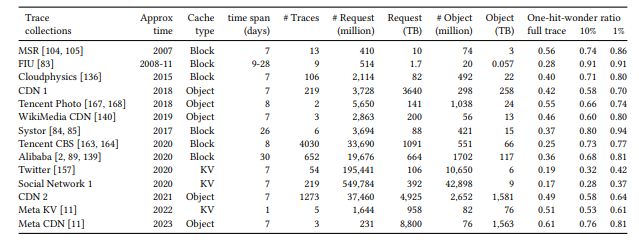
Our insight is that a cache experiences more one-hit wonders than what common full trace analyses suggested, highlighting the importance of swiftly removing most new objects. Specifically, we observe a median one-hit-wonder ratio of 26% across 6594 production traces”
Rough Sketch — Assume a cache size of and an almost uniform distribution (e.g. ). Then at least keys are never OHWs. Approx are never seen and thus cannot be OHWs (ever elusive!). The distribution of the of each of the remaining keys is . We (crudely) assume an LRU eviction algorithm and no temporal correlation s.t. is the probability of reappearing in the stream of requests before other unique keys are seen…
This is about what we’d expect based on (2), though perhaps a bit high. If I’ve read the paper correctly there are a few possible reasons for this:
Their definition of includes items that are requested once and not requested again before being evicted from the cache. I’ve ignored cache capacity , but it’s clearly a determining factor. Implicitly, we’ve assumed that . In practice we’d expect .
This is a glaring one. The denominator in their OHW ratio keys that don’t make an appearance at all. I’ve treated as a known value, but in practice it’s unlikely the set of keys will be so well defined. This is probably the correct choice and if I followed this convention my estimate would increase to about . Yeesh!
Given these caveats and my assumptions, I’m reasonably confident in my upper bound from . In practice it seems we can’t avoid specific properties of the cache. A good next step would be to determine the distribution of requests needed to see unique values given some arbitrary distribution over a set of keys.