I was in Madrid recently and skimmed On The Probability Of A Pareto Record on the plane back home. The notes below cover two questions I had about independent Pareto points. Consider , we say if for and call a pareto point of if for , there is no point satisfying .
— There’s also a (very handy!) video from a Fields Institute Analysis of Algorithms conference where Fill describes the main results of On The Probability Of A Pareto Record. The bound I give in is corroborated in of the paper and briefly mentioned in the video.
— Assuming the following, what’s the probability that the point observed is pareto?
Notice that greatly depends on the norm of . To compute the probability that a point is pareto, we integrate the product of the probability a point has norm equal to and the probability that none of the preceding points dominate .
To simplify the integral notice that the second term is strictly increasing on , and satisfies and . Thus, instead of integrating a product, we’ll just integrate the right tail of the Erlang pdf on .
— I use because approximates the median of the second term. I could be a bit more rigorous and integrate from , but for we’ll be better off with the first approximation.
After zooming through a few mechanical steps we arrive at an asymptotic bound for that agrees with in Fill’s paper and the main result of Barndorff-Nielsen and Sobel’s On the distribution of the number of admissible points in a vector random sample.
— I’ll call the of a point in a set () the number of successive layers of pareto points that must be removed from before becomes pareto in the remaining subset. Given , a newly-observed pareto point of with , what is the expected depth of after an additional points are observed?
Notice that the probability of is . Over observations, this implies that the size of the set of points that dominate is distributed by .
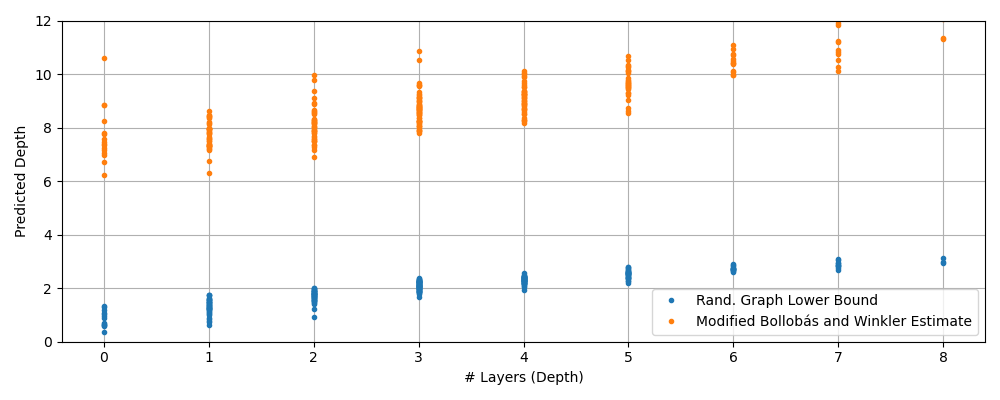
Hand-waving a bit, most pairs in this set will be non-comparable (i.e. ) and a small fraction, , will satisfy . If we treat the set of points that dominate as a probabilistic graph, we get a lower-bound that’s logarithmic in .
Even better! Recall that random graphs have . Voila! Done! However, our real graph has a lot more structure than one with randomly assigned edges. I’d conjecture that the actual depth of is proportional to the number of layers in a non-dominating sort of the points dominating .
— I did what you might call “vibe-bounding” above. Fortunately for me, finding the number of layers in non-dominating sort is a research question on it’s own. When is large, this is approximately equal to the length of the longest chain from to the pareto front. In The Longest Chain Among Random Points In Euclidean Space, the authors show depth is when sampling uniformly from . We can map exponential coordinates to easily with the CDF, but sampling uniformly from the cube may be more challenging. Let’s define as the projection of onto the diagonal of the -dimensional unit cube.
This transform shrinks (even when coordinates are transformed back into ), but it ensures we’re considering points in the cube . We now proceed with the bound proposed in Bollobás and Winkler using the point to estimate the size of the dominating set.
d = 5
b = 2 ** -d
m = 2**12
data = []
for x_n in np.random.exponential(1.0, size=(1024, d)):
samples = np.random.exponential(size=(m, d))
# Lower-Bound: Function of L1 norm – Assumes Random Graph
l1_norm = np.sum(x_n)
y0 = 1 - np.log(m) / np.log(b) + l1_norm / np.log(b)
# Upper-Bound: Function of Transformed L1 norm
v = transform(x_n)
y1 = np.exp(1) * (m * np.exp(-np.sum(v))) ** (1 / d)
# Actual: Compute Depth via Non-Dominating Sort
dom = dominating_subset(samples, x_n) # Subset of `samples` which dominate x_n
layers = non_dominated_sort(dom) # Claude wrote the NDS algorithm, I trust Claude, but YMMV
x = len(layers)
data.append((x, y0, y1))