Consider an inverted index that maps words to a postings list: the set of document IDs in which that word appears. In this scheme, IDs are assigned sequentially such that an index with documents necessarily has a document identified by each integer on .
An operation we might be interested in performing is an intersection query. We can complete a query with unique words by accessing each word’s postings list and successively taking no more than set intersections. Specifically, is the intersection of all postings lists acquired by . Perhaps this optimization is already clear to you, but I claim that in expectation, a query’s intersection cost can be improved by sorting the results of such that postings lists are processed in increasing order.
— I am not claiming that it’s always worth it to sort. As expected with any sort operation, we have cost. Whether this dominates the (alleged) improvement to intersection performance is up to the specific properties of the index and corpus.
Let’s start with a bound that (we will soon see) is too loose to matter. This is a false start, but perhaps it gives us some good intuition about what we need to analyze. Recall that set intersection using the standard merge algorithm has complexity , where and are the left and right operands in a foldl-style operation.
If we’ve already fetched all postings lists, we have a collection of postings lists such that . When these postings lists are sorted by length, it follows that and therefore is an upper bound. In the unsorted case, we can make a similar argument, but we can only assert that . In any event, the bound is still proportional to the sum of postings list sizes. Unfortunately, this result doesn’t really support the claim I’m making…
— The last fact follows from the observation that the left operand is an intersection over iid draws from some distribution and the right operand is a single draw from the same distribution. Perhaps I am being too sloppy here, but I implicitly assume that the distribution of postings lists is roughly iid from an (unknown) distribution, . I believe that G.K. Zipf (of the distribution) computed that English word frequency was near , but that’s not so helpful for us as it ignores document length and correlation.
Let’s consider an alternative argument. Because the left operand is non-increasing in size, the most conservative construction is one where remains unchanged through all folds. This occurs when the postings lists form a chain in :
In this case, the cost is . If is known, we can use order statistics to characterize . For example, if , then the minimum of iid draws satisfies , giving us a total cost bounded by . In the case, the left operand is no longer the global minimum of draws but the running minimum up to the fold. This is distributed as . Integrating, this gives a total cost of , where is the -th harmonic number. In this specific case, sorting yields an improvement proportional to . Generalizing:
where with all drawn iid from .
Fortunately for us, language has structure and this chained construction’s limited improvement represents the worst-case rather than a realistic scenario. Let’s analyze the other extreme, complete independence. Consider the case where each postings list is a random sample of indexes on . In this model, each document is included in a word’s postings list independently with probability (where is the mean postings list size). In the unsorted case this yields a left operand which, in expectation, shrinks geometrically by a factor of per fold.
Working through the algebra, we arrive at a bound of . We apply a similar trick to determine the complexity of intersections of length-sorted postings lists. Let where . Applying the same analysis…
Finally, we do a bit of the s-word (s*mulation)
to verify that the realized execution time roughly tracks the
theoretical bounds. I am not a Python performance expert, I cannot
defend the below as the most efficient implementation of this scheme,
but I suspect it’s “close enough” to see the effects we’d
like…
import functools
import numpy as np
import math
import time
import matplotlib.pyplot as plt
LAMBDA = 0.25
N_POSTINGS_LISTS = 5
N_SAMPLES = 16 * 1024
DOCUMENT_ID_SPACE_SZ = 1024
RNG = np.random.default_rng()
# This is more natural, but w.o. the early return we kinda smear performance...
# See `foldl_intersection` def'n below...
#
# def foldl_intersection(sets):
# return functools.reduce(lambda acc, s: acc & s, sets)
def foldl_intersection(sets):
it = iter(sets)
try:
acc = next(it)
except StopIteration:
return set()
for s in it:
acc &= s
if not acc:
return set()
return acc
def chain_sampler(arr: list[int], n: int, sort: bool = False) -> list[set[int]]:
ll = len(arr)
bnd = RNG.exponential(ll * LAMBDA, n)
if sort:
bnd.sort()
return [set(arr[:min(math.ceil(b), ll - 1)]) for b in bnd]
def unif_sampler(arr: list[int], n: int, sort: bool = False) -> list[set[int]]:
ll = len(arr)
bnd = RNG.exponential(ll * LAMBDA, n)
if sort:
bnd.sort()
return [set(RNG.choice(ll, size=min(math.ceil(b), ll - 1), replace=False).tolist()) for b in bnd]
def time_folds(sampler, sort: bool) -> np.ndarray:
arr = list(range(DOCUMENT_ID_SPACE_SZ))
samples = [sampler(arr, N_POSTINGS_LISTS, sort=sort) for _ in range(N_SAMPLES)]
times = np.empty(N_SAMPLES)
for i, lists in enumerate(samples):
t0 = time.perf_counter_ns()
foldl_intersection(lists)
times[i] = time.perf_counter_ns() - t0
return times
fig, axes = plt.subplots(1, 2, figsize=(12, 4), sharey=True)
for ax, (name, sampler) in zip(axes, [("chain", chain_sampler), ("unif", unif_sampler)]):
unsorted_times = time_folds(sampler, sort=False)
sorted_times = time_folds(sampler, sort=True)
ratio = np.median(unsorted_times) / np.median(sorted_times)
lo = min(unsorted_times.min(), sorted_times.min())
hi = max(unsorted_times.max(), sorted_times.max())
bins = np.logspace(np.log10(lo), np.log10(hi), 60)
ax.hist(unsorted_times, bins=bins, alpha=0.5, label='unsorted')
ax.hist(sorted_times, bins=bins, alpha=0.5, label='sorted')
ax.set_xscale('log')
ax.set_xlabel('ns per foldl_intersection')
if name == "chain":
ww = math.log(N_POSTINGS_LISTS)
else:
ww = N_POSTINGS_LISTS
ax.set_title(f"{name}_sampler (median ratio: {ratio:.2f}x, proj: {ww:.2f}x)")
ax.legend()
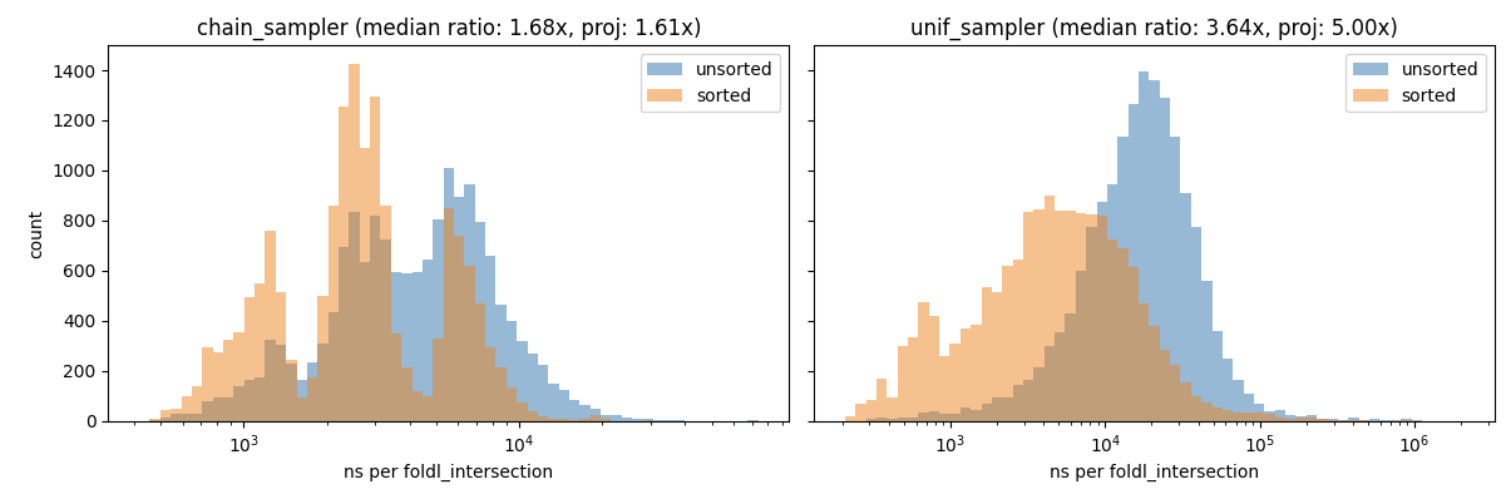
Looks “close enough” to me! We observe about a improvement vs. predicted. The uniform case lands at against a theoretical ceiling of . And again, because I can’t really vouch for anything that’s going on under the hood, we ought to treat this analysis as mild supporting evidence for the bounds from earlier in the post. If I get some time later this week I’ll write a real implementation in Go or Rust.