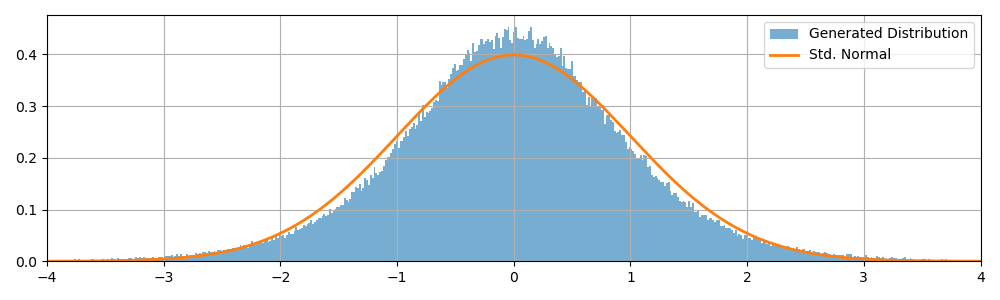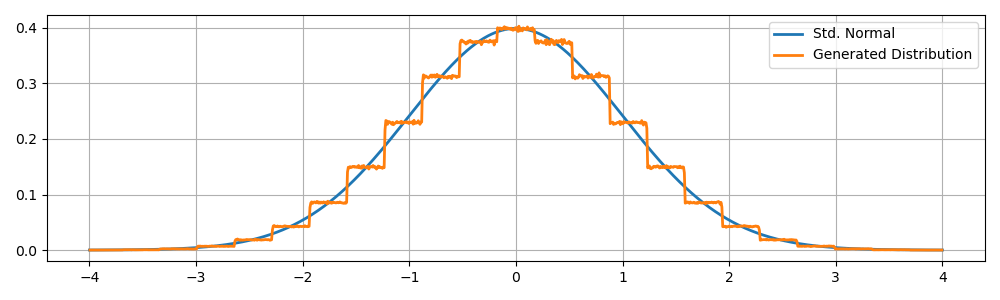
In many settings where normally distributed values are called for, “approximately normal” values will suffice (e.g. as in Database-Friendly Random Projections [1]). Today, I’ll describe a method that’s (a little) faster than the and implementations and approximates the standard normal distribution.
Our goal is to use one call of to generate values that are distributed by . The number of set bits in the first is distributed by and the remaining bits are used to generate . We can then center and scale the intermediate distribution and return a value with zero mean and unit variance.
const c0 = 0.35172622 // 1.0 / math.Sqrt(8. + 1./12.)
const c1 = 1.0 / float64(1<<32)
// Draws from an Approx Normal distribution, if you're creative it resembles a terraced garden.
func ApproxNormF64(r *rand.Rand) float64 {
u := r.Uint64()
uhi, ulo := uint32(u>>32), uint32(u)
return c0 * (float64(bits.OnesCount32(uhi)) + c1*float64(ulo) - 16.5)
}
Unfortunately, we get an underwhelming speedup against . To go faster, we could use all 64 bits to generate variables distributed by , but I found this was only faster than ’s implementation and much further from than .
go test -bench GenRandNorm -benchtime=10s -cpu=1
Benchmark_Distuv_GenRandNorm 1000000000 8.166 ns/op
Benchmark_MathRand_GenRandNorm 1000000000 4.717 ns/op
Benchmark_Approx_GenRandNorm 1000000000 3.600 ns/op
Benchmark_Bin64_Approx_GenRandNorm 1000000000 2.655 ns/opWe now turn to the important question of “Is this actually any good?”. Using and to denote the generated distribution. Notice that:
Taking these observations together, we can bound by computing the maximum possible height of a triangle formed between and .
We can also bound the maximum sampling error over a contiguous interval by finding the max area for such a triangle. For any , we have:
— This implementation described on Reddit is identical to what I propose here. In fact, the post heped me catch an error in my work where I neglected the contribution to variance from . My sincerest thanks to u/Dusty_Coder and u/skeeto.
— Another zany (slow!) way to generate approximately normal random variables is to generate uniform random variables, sort them, and apply the following transform to the largest. I can’t imagine why you’d ever use want to this method, but it’s there if you want it…
This method just approximates the CDF of the normal to and makes use of properties of order statistics of the uniform distribution. The transform above is just the approximate quantile function of the normal.