I worked on this over 2 days of a company hackathon. This post is almost verbatim ripped from my notes. The implementation is available here and as a gist.
If we have a producer process () which sends messages to a consumer () on an unreliable link, there will occasionally be outage periods where the link between and fails and must either 1) drop messages, 2) buffer messages locally, or 3) stop generating messages.
There can be good reasons for a system to choose or , but I’m most interested in better ways to implement . I noticed that a few popular metrics-streaming clients offered relatively limited options for how to buffer messages. For example, both DataDog’s Vector, and Fluent only support:
For some applications, recovering roughly evenly spaced data may be preferred to recovering messages from the beginning or end of the outage. I wanted to see if I could write a buffer that uses fixed memory and keeps a random, uniform sample of messages during an outage of arbitrary length.
If my buffer is configured to store up to 64 messages, and an outage lasts messages, every message will be preserved and it acts in the same way as an unbounded buffer. If my buffer is presented with a 1024 message long outage, it preserves 64 random messages with an expected gap of 16 messages between retained messages.
Because there’s know way for the client to know how long an outage will last beforehand, we cannot just sample every message. To sample approximately uniformly, I pulled out an old algorithm called .
— The Wikipedia page on reservoir sampling mentions a few algorithms - and . They are equivalent, and I implemented L, but it’s probably overkill unless the stream is exceptionally high volume. Algorithm L minimizes calls to when outages are long and the buffer is small, while R must call on each message seen. At low volumes this doesn’t make much of a difference, and algorihtm R is much easier to implement and debug. Furthermore, because I take locks to make it safe for concurrent access I probably wash away any performance improvement we’d get from L anyway.
I was able to get this working locally, but was not able to implement it in in time because of .
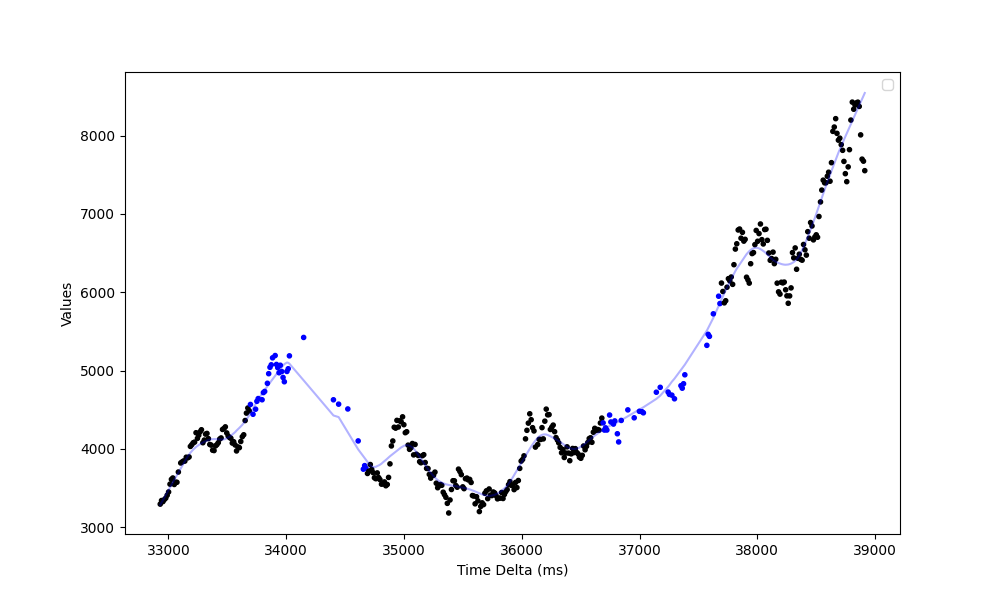
During the local test, I had a client send messages every 5ms and had the server reject messages for 1s intervals every 3s. Observations in black were collected in-order as part of the normal operating periods, the blue observations (notice that these periods are sparser!) represent values that are backfilled from the buffer after the “outages” have cleared.
There are a few places where this should be tidied up:
I don’t properly support concurrent writers, though I argue we probably shouldn’t need concurrent writers.
I assume outages don’t flap - i.e. once
reservoir.Read(0) succeeds, I assume subsequent
reservoir.Read(n) calls will succeed as well. I don’t like
this assumption much. Oh well.
I’m sure it’s close to correct, but I’m sure there are correctness bugs in there.